




What do you do when you want to export all or specific links from a webpage? Copying them one after another is monotonous and useless especially when you can automate it with a line of JavaScript code. This article serves as a short demonstration of how you can use browser developer consoles to scrape data from the web page. If you are impressed with this, do learn some JavaScript as it comes very handy. Two other techniques to extract links from page are also shared here for people who don’t want to get their hands dirty with code 😄.
Extracting URLs using Dev Tools console
The browser console is an excellent tool to test and debug things. You can write JavaScript code and inject it into the current page to do all sorts of fancy things. I can’t stress enough how useful that is! To open the console on Chrome, press Cmd + Shift + i on Mac and Ctrl + Shift + i on Windows. The JavaScript snippets to extract links are given below. Copy the code, paste it into the console and hit enter.
Extract URLs + Corresponding Anchor Text
The following is a cross-browser supported code for extracting URLs along with their anchor text.
var urls = document.querySelectorAll('a');
for(url in urls){
console.log("#"+url+" > "+urls[url].innerHTML +" >> "+urls[url].href)
}Extract URLs + Corresponding Anchor Text – Styled Output (For Chrome & Firefox)
If you are using Chrome or Firefox use the following code for a styled version of the same.
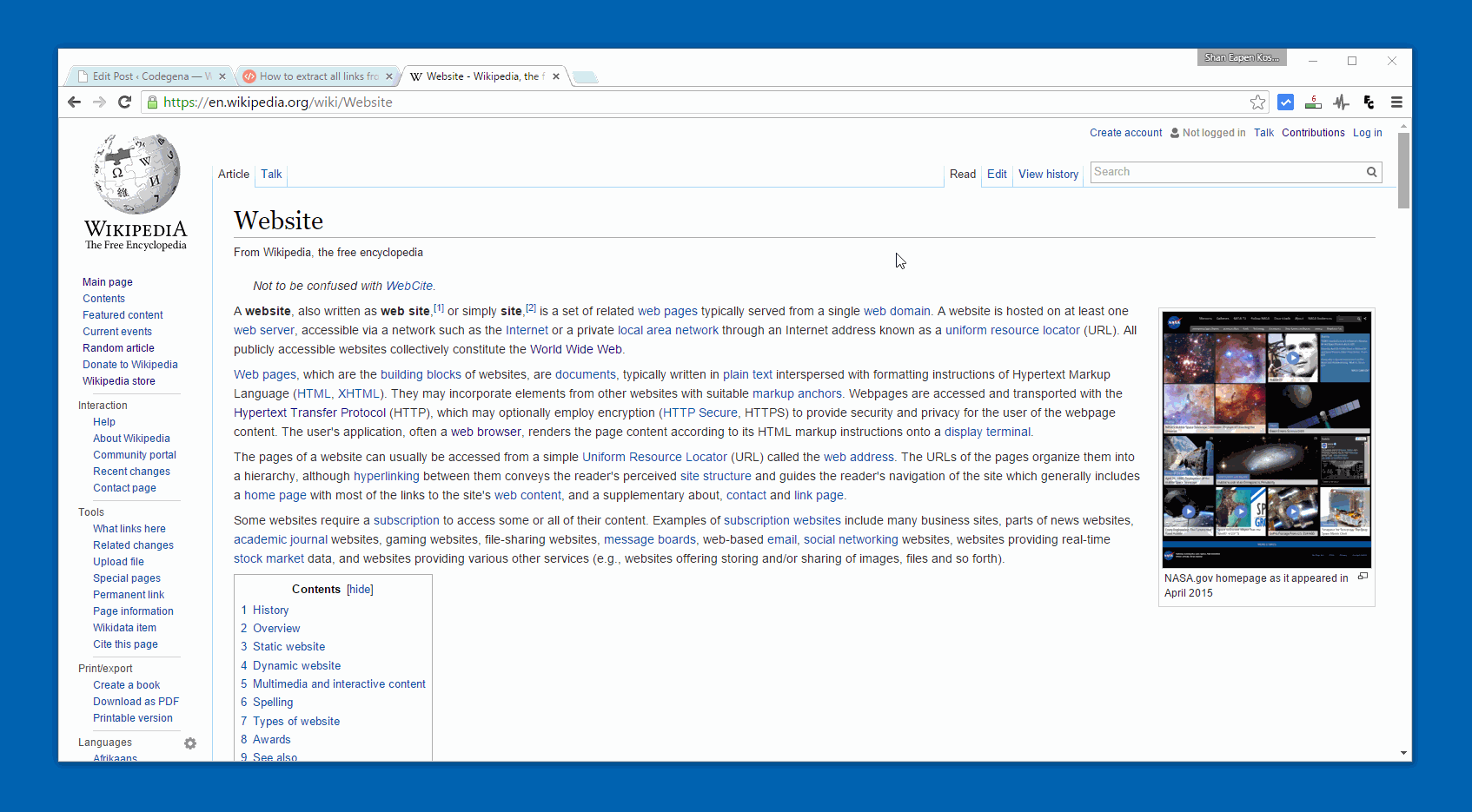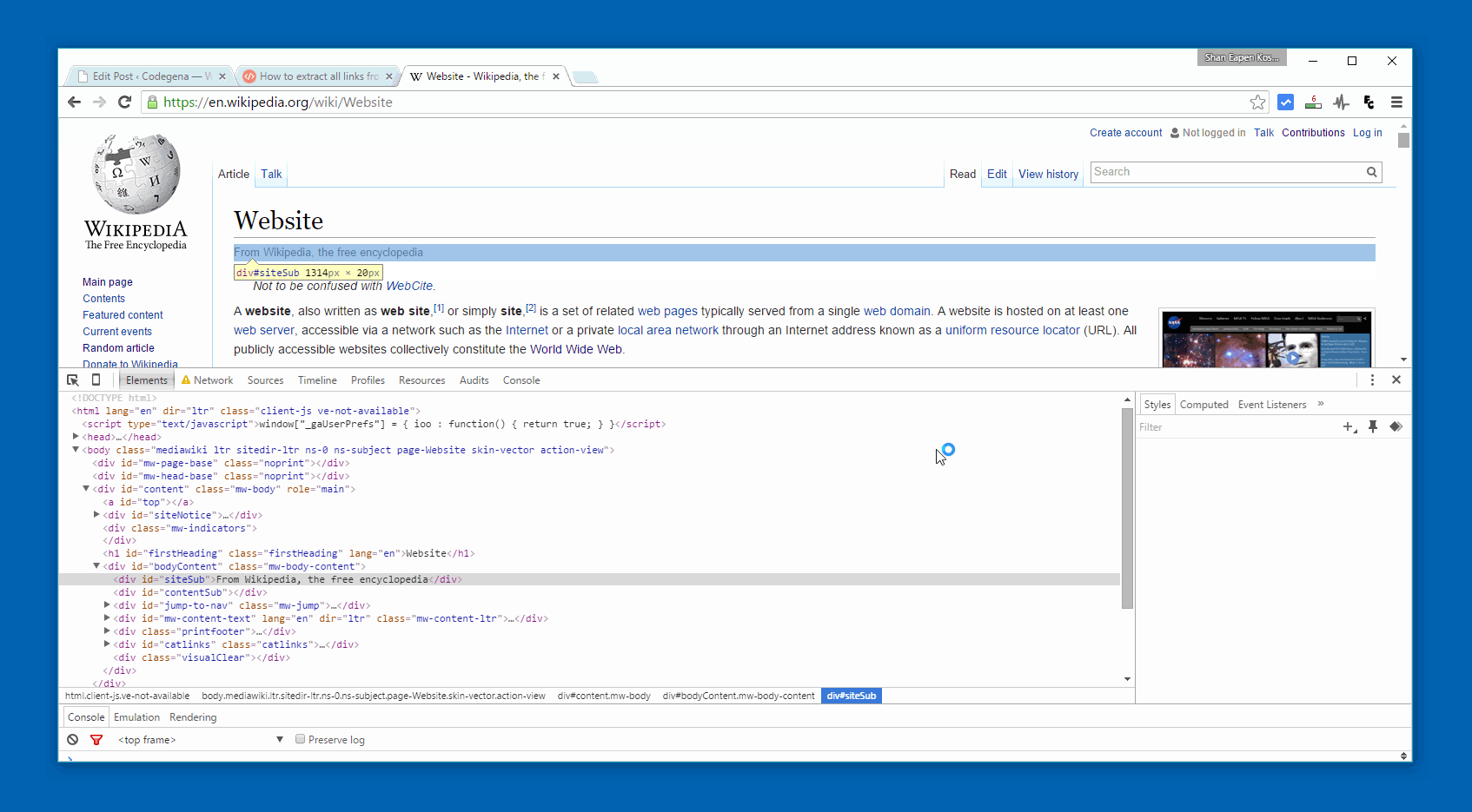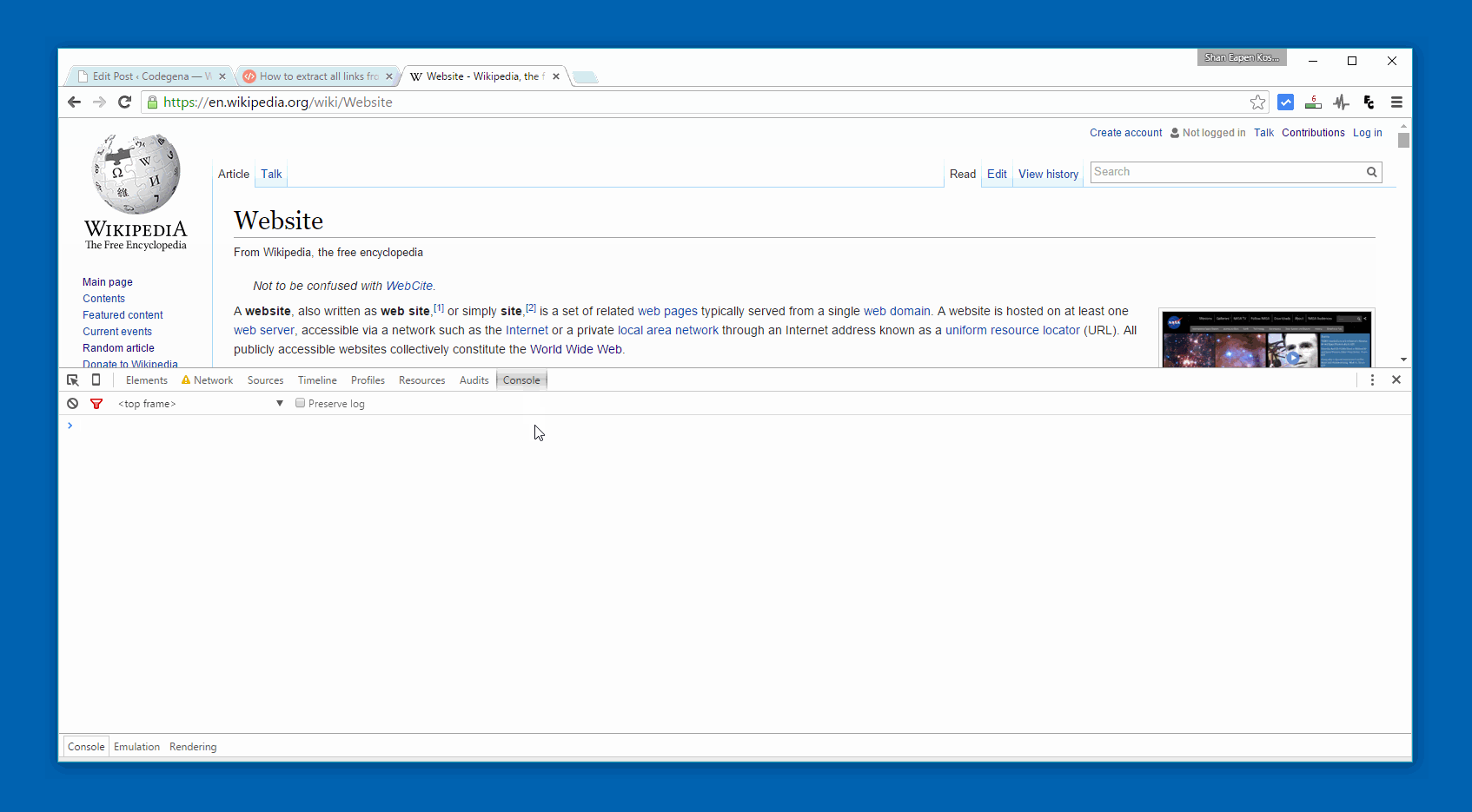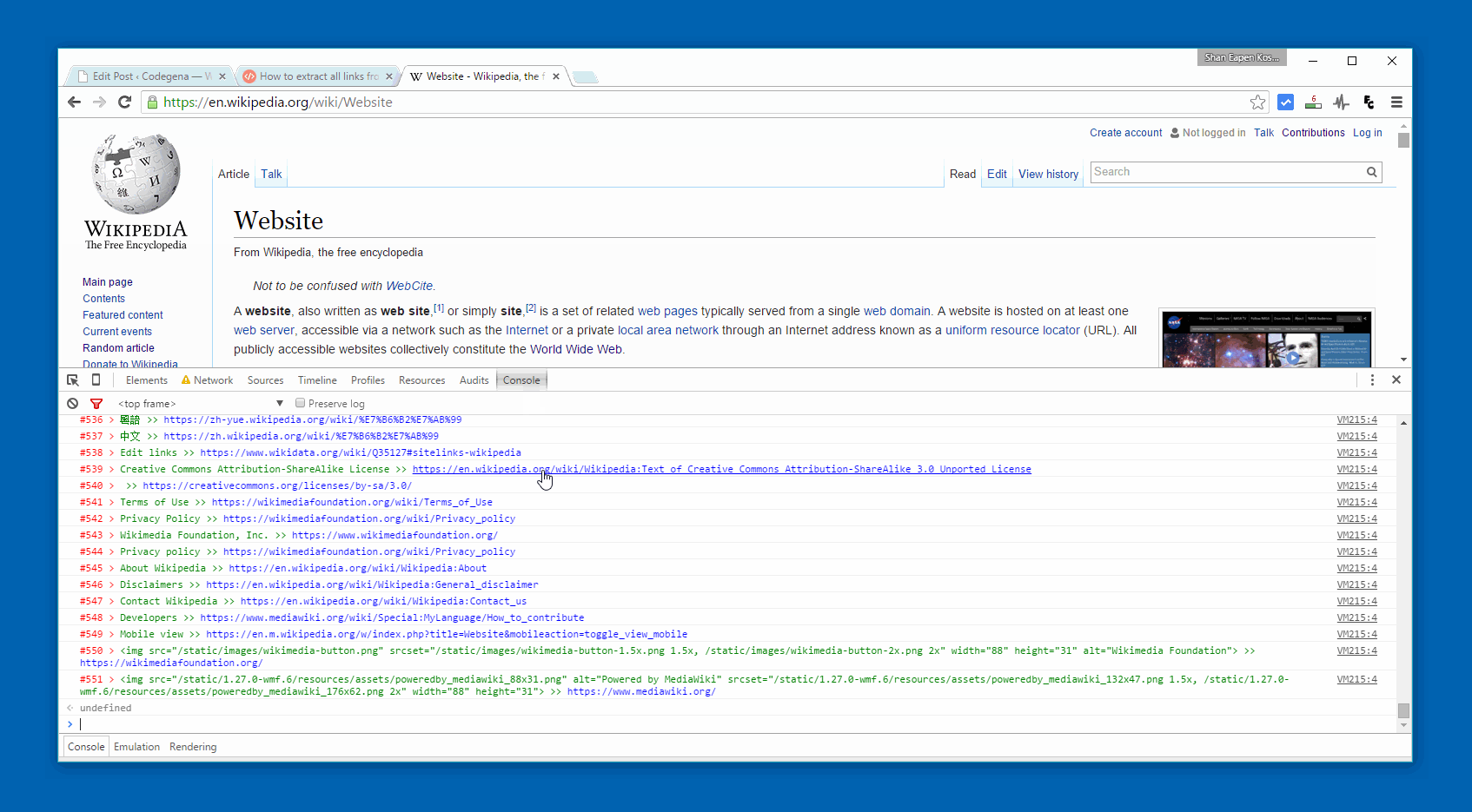
var urls = document.querySelectorAll('a');
for(url in urls){
console.log("%c#"+url+" > %c"+urls[url].innerHTML +" >> %c"+urls[url].href,"color:red;","color:green;","color:blue;");
}Extract URLs Only
And if you want to extract just the links without the anchor text, then use the following code.
var urls = document.querySelectorAll('a');
for(url in urls)
console.log(urls[url].href);Extract External URLs Only
External Links are the ones that point outside the current domain. If you want to extract the external URLs only, then this is the code you need to use.
var links = document.querySelectorAll('a');
for (var i = links.length - 1; i > 0; i--) {
if (links[i].host !== location.host) {
console.log(links[i].href);
}
}
Extract URLs with a specific extension
If you would like to extract links having a particular extension then paste the following code into the console. Pass the extension wrapped in quotes to the getLinksWithExtension() function. Please note that the following code extracts links from HTML link tag only (<a></a>) and not from other tags such as a script or image tag.
function getLinksWithExtension(extension) {
var links = document.querySelectorAll('a[href$="' + extension + '"]'),
i;
for (i=0; i<links.length; i++){
console.log(links[i]);
}
}
getLinksWithExtension('mp3') //change mp3 to any extension
Online URL Extractor Website
There are situations when you cannot follow the above method such as when you are using a mobile. In situations like that, you can follow this trick. iwebtool is a great site that offers URL extraction along with other features such as selective extraction of inbound or outbound links, anchor text extraction, etc. You can make 10 requests per hour with the free version of the tool. Visit iwebtool link extractor to get started. Enter the url in the text box and wait for the site to extract the links.
Extract URLs from a block of text
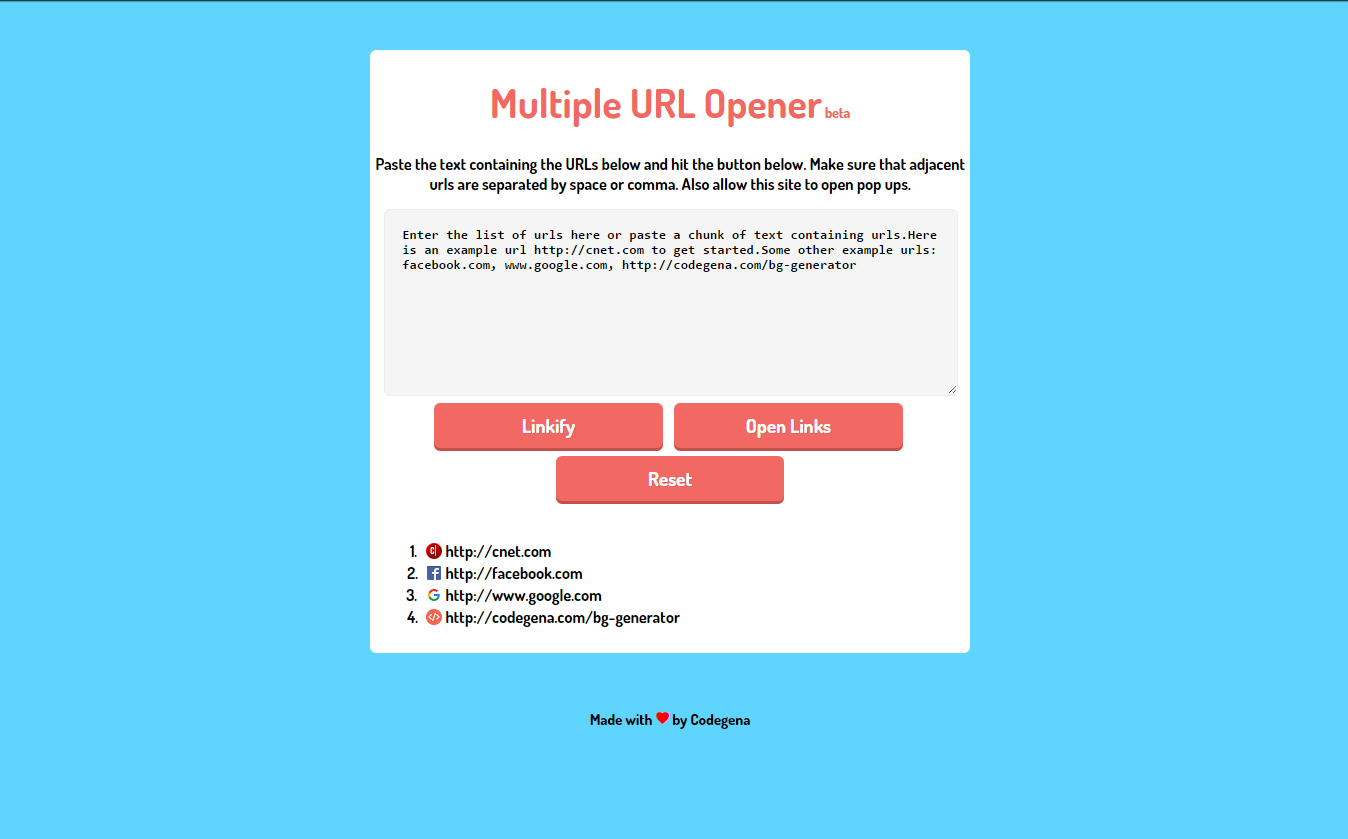
Let’s say you’ve got a text file with a bunch of links in it. In such cases, you can use our free web tool to extract and open multiple URLs from texts.
- Go to Codegena URL Extractor and bulk URL opener
- Paste the text into the text area and hit Linkify to generate clickable links.
- Click on “Open all URL” button to automatically open all of the links in new tabs (allow popups to enable this feature)
You can also paste the source code of a website into this tool to extract the urls from it. However in such cases this tool will fail to extract relative links.
A similar tool is BuzzStream URL Extractor which also offers CSV export.
If you need any assistance, leave a comment below and I will get back to you.
Also Read




this is result of your code on this site:https://www.dudemobile.net/cl.php?id=8ab158761ba9eb7fcd38d98a4294a534
“undefined”
“Uncaught (in promise) DOMException: Failed to register a ServiceWorker: No URL is associated with the caller’s document”
“Uncaught SyntaxError: Unexpected identifie”
please explain properly n stepwise…….
There are no URLs to extract from that site. That’s why it returned an error.
Hi
I know it´s an old threat but how can it be that the excact url extract doesnt show the same amount as an site:xxx?
And thanks for great tips :-)
it´s regarding tilbuds-portalen.dk, this extract shows about 66 and a site:tilbuds-portalen.dk shows 177
all medthod cannot extract url type “onclick” in sourcecode i am super surprise !!!!!!!!!!!!!!
you try go to any web which contain url of id line which it is this format
onclick=”location.href=’http://line.me/ti/p/~petermarrylove789′”
your method can not extract this url !!!
pls help me too. thank you very much